
Bài viết được cập nhật ngày 27/01/2024
Đối với các SEOer hay Marketer chuyên nghiệp thì thuật ngữ Crawl không còn quá xa lạ. Tuy nhiên, với những ai mới tìm hiểu về SEO thì các khái niệm Crawl hay Web Crawler còn khá mơ hồ và khó hiểu. Và có bao giờ bạn thắc mắc tại sao Google có thể đọc được thông tin trên Website của bạn không? Cùng EZ Marketing tìm hiểu chi tiết hơn về các thông tin hữu ích này nhé.
Nội dung bài viết
Crawl là gì? Web Crawler là gì?

Crawl là gì? Web Crawler là gì?
Crawl là gì?
Crawl là một thuật ngữ khá quen thuộc trong SEO, đây được hiểu là hành động thu thập dữ liệu trên các Website của các con bot do các công cụ tìm kiếm sử dụng.
Cụ thể, Google sẽ tung ra hàng triệu con bot nhỏ luồn lách vào bên trong các Website. Nhiệm vụ của chúng là lần lượt truy cập vào từng liên kết trên các trang đó cho đến khi hết, tiến hành thu thập dữ liệu, phân tích các mã nguồn HTML để đọc dữ liệu. Cuối cùng, gửi về máy chủ những dữ liệu đã thu thập được để công cụ tìm kiếm phân tích và quyết định index Website(Index là quá trình thêm các trang Web vào Google Search).
Đây chính là lý do vì sao website của bạn cần có sitemaps(bản đồ website). Vì chúng chứa tất cả những URL trên website của bạn, giúp con bot có thể đọc hiểu được toàn bộ nội dung trên Website.
Web Crawler là gì?
Web Crawler còn có các tên gọi khác là Spider, robot, bot công cụ tìm kiếm…Tất cả những từ trên đều có nhiệm vụ chung là tải xuống và index thông tin ở mọi nơi trên Internet.
Quy trình Crawling của Google Bot?
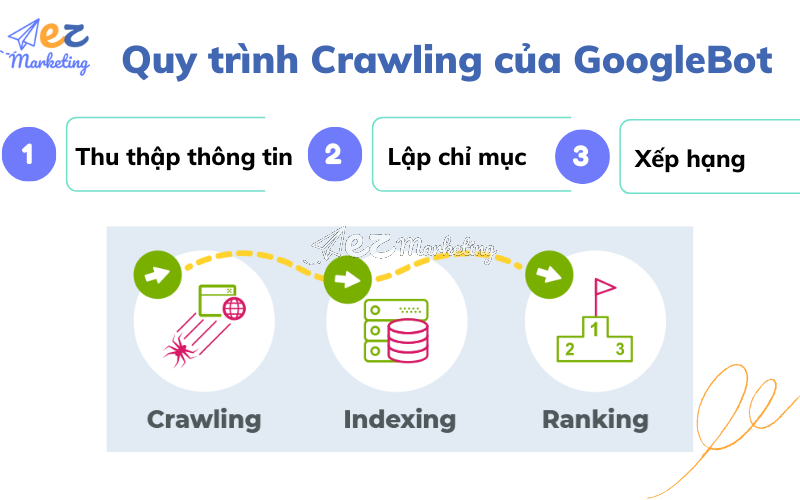
Quy trình Crawling của Google Bot?
Hiện nay, Google Bot được xem là một trong những công cụ thu thập dữ liệu tốt nhất của Google. Quy trình Crawl một Website bao gồm các công việc chính là thu thập thông tin, lập chỉ mục và tiến hành đưa ra xếp hạng cho Website trên công cụ tìm kiếm. Cụ thể, quy trình crawl gồm 3 bước như sau:
- Thu thập thông tin: Đầu tiên, Google Spider sẽ tiến hành truy cập vào từng liên kết trên trang để thu thập thông tin. Những Website này thường là kết quả của những lần thu thập trước hoặc do người dùng gửi trên các công cụ Google Search Console. Con bot sẽ rà soát toàn bộ các liên kết trên trang, ưu tiên những liên kết mới nhất. Việc này tương tự như khi bạn rà soát nội dung trên Website.
- Lập chỉ mục: Sau khi đã thu thập toàn bộ dữ liệu trên Website, những thông tin này sẽ được gửi về máy chủ để tiến hành kiểm tra và lập chỉ mục, đánh giá chất lượng của từng trang Web trên website của bạn.
- Xếp hạng: Quy trình Crawl sẽ thu thập toàn bộ dữ liệu đó kèm theo các yếu tố bên ngoài của Website như số lượng backlink trỏ đến trang, lượng truy cập vào trang Web. Sau đó gửi toàn bộ thông tin này về ngân hàng dữ liệu để tiến hành đánh giá và xếp hạng cho Website.
Các yếu tố ảnh hưởng đến quá trình Web Crawler?

Các yếu tố ảnh hưởng đến quá trình Web Crawler?
Hiện nay, số lượng người dùng Internet vô cùng lớn. Chính vì thế, số lượng trang Web trên thế giới này cũng lên đến hàng triệu triệu Website. Vậy có phải tất cả các trang Web đều được Google Index hay không? Nếu là một người làm SEO, có bao giờ bạn thắc mắc tại sao Website của mình không được Crawl và Index?
Thực tế, quá trình Web Crawler sẽ bị ảnh hưởng bởi các yếu tố sau:
- Domain: Tên miền là một yếu tố quan trọng trong Website, để giúp trang Web được Crawl tốt hơn thì bạn nên đặt tên miền có chứa từ khóa chính của doanh nghiệp. Khi đó, chắc chắn vị trí xếp hạng trên công cụ tìm kiếm của Website cũng sẽ cao hơn.
- Backlink: Backlink là yếu tố quan trọng để đánh giá chất lượng và độ uy tín cho một website. Một Website được cho là đáng tin cậy và cung cấp nhiều thông tin hữu ích sẽ cần chứa nhiều backlink chất lượng trỏ đến, lượng khách hàng truy cập lớn. Nếu website của bạn không có bất cứ backlink nào thì sẽ bị Google đánh giá rằng bạn cung cấp nội dung không chất lượng.
- Internal link: Không chỉ liên quan đến Web Crawler, các liên kết nội bộ trong website luôn là yếu tố không thể thiếu. Những internal links sẽ làm tăng thời gian truy cập của người dùng trên site, tăng lượng traffic và điều hướng người dùng đến các trang khác có liên quan trên Website của bạn.
- XML Sitemap: Việc thiết lập một bản đồ trang Web tự động sẽ giúp quy trình Crawl và Index diễn ra nhanh chóng hơn. Google sẽ được thông báo là trang Web của bạn đã được cập nhật và ưu tiên Index những nội dung mới trước.
- Duplicate content: Để website của bạn được đánh giá tốt thì bạn cần rà soát toàn bộ nội dung được đăng tải trên website, tránh trường hợp nội dung bị trùng lặp. Nếu xảy ra, có thể Website sẽ bị Google block và nguy hại hơn còn bị biến mất của công cụ tìm kiếm.
- URL: Đây là yếu tố có ảnh hưởng trực tiếp đến cả quá trình SEO và chất lượng website. Bạn cần tạo URL thân thiện với SEO để Website được xếp hạng cao hơn.
- Meta tags: Các thẻ meta(meta title, meta description…) trong trang cần phải thật độc đáo và ấn tượng để giúp Website của bạn được Google xếp hạng vị trí cao nhất.
Đây là 7 yếu tố quan trọng bạn cần tối ưu để Google có thể thực hiện Crawl và Index trang Web nhanh chóng và hiệu quả hơn.
Crawl ảnh hưởng đến SEO như thế nào?

Crawl ảnh hưởng đến SEO như thế nào?
Thực tế, quy trình Crawl dữ liệu của các công cụ tìm kiếm có ảnh hưởng rất lớn đến quá trình SEO.
Khi thực hiện SEO một Website, nghĩa là bạn đang sản xuất ra các nội dung có chất lượng để đáp ứng đúng search intent của người dùng. Đây là tài nguyên giúp trang được index và hiển thị trên các công cụ tìm kiếm.
Tuy nhiên, nếu Googlebot không thực hiện thu thập dữ liệu trên Website của bạn thì quá trình index sẽ không xảy ra. Như vậy trang của bạn sẽ không xuất hiện trên các công cụ tìm kiếm.
Chính vì thế, nếu bạn đang là chủ doanh nghiệp, bạn muốn nhận được lượng truy cập không phải trả phí thì bạn không nên chặn Crawl dữ liệu.
Làm thế nào để ngăn Google Crawling những dữ liệu không quan trọng trên Website?

Làm thế nào để ngăn Google Crawling những dữ liệu không quan trọng trên Website?
Nếu bạn đang trong quá trình cập nhật Website hoặc không muốn Google Crawling những dữ liệu không quan trọng thì làm như thế nào?
Dưới đây là 3 giải pháp dành cho bạn:
- Sử dụng robots.txt
- Sử dụng thẻ noindex
- Sử dụng Plugin Yoast SEO
Bạn có thể xem chi tiết trong bài: Các cách chặn Google index website nhanh nhất
Trước khi quyết định có nên chặn Google Spider thu thập dữ liệu trên website của bạn hay không thì bạn cần kiểm tra lại toàn bộ Website để có lựa chọn chính xác. Ngoài ra, nếu bạn thắc mắc tại sao Googlebot không thực hiện Index trang của bạn thì cần rà soát lại xem bạn có đang chặn chức năng thu thập dữ liệu không. Và nội dung trên trang đã đủ uy tín và chất lượng để cung cấp cho người dùng hay chưa.
Tóm lại, Crawl là một trong những yếu tố quan trọng ảnh hưởng trực tiếp đến kết quả xếp hạng của Website trên các công cụ tìm kiếm. Hy vọng những thông tin trên đây của EZ Marketing sẽ giúp bạn hiểu hơn về các thuật ngữ quan trọng trong SEO. Chúc bạn thành công và đạt được những thành quả nhất định nhé.



Hãy để lại bình luận