
Bài viết được cập nhật ngày 16/07/2023
Bạn nghe thấy mọi người bảo sử dụng file Robots.txt để chặn Google index? Nhưng bạn không biết file Robots.txt là gì và cách tạo file đó như thế nào? Cách sử dụng Robots.txt như thế nào? Tất cả sẽ có trong bài viết này!
Nội dung bài viết
- File Robots.txt là gì?
- File file robots.txt dùng để làm gì?
- Xem file robots.txt trên Website của bạn như thế nào?
- Cấu trúc của file robots.txt
- Cách tạo file Robots.txt như thế nào?
- Dùng file Robots.txt để chặn các công cụ khác thu thập dữ liệu từ Website của bạn
- Làm sao để chặn Ahrefs và Semrush nhưng không chặn Google index Website của mình?
- 6 câu hỏi thường gặp nhất về file robots.txt
- 1. Website của tôi có bắt buộc phải có file robots.txt không?
- 2. Tôi có thể đặt File robots.txt trong một thư mục con không?
- 3. Tôi muốn chặn người khác đọc file robots.txt có được không?
- 4. Tôi có phải đưa vào một lệnh Allow để cho phép trình thu thập dữ liệu không?
- 5. Điều gì sẽ xảy ra nếu file robots.txt của tôi chứa lỗi?
- 6. Nếu tôi thay đổi các lệnh trong file robots.txt thì mất bao lâu để những thay đổi đó của tôi tác động đến kết quả tìm kiếm?
File Robots.txt là gì?
File Robots.txt được các người sở hữu Website sử dụng với mục đích chủ yếu để ngăn chặn các công cụ, các trình thu thập dữ liệu thu thập dữ liệu từ Website của họ.

File Robots.txt nhằm mục đích ngăn chặn các công cụ, các trình thu thập dữ liệu thu thập dữ liệu từ Website
Ví dụ: Khi Website của bạn chưa được hoàn chỉnh, và bạn không muốn Google index các nội dung trên Website của bạn, thì bạn sẽ dùng File Robots.txt để chặn Google index Website của bạn.
Một ví dụ khác: Bạn không muốn đối thủ có thể phân tích Website của bạn thông qua công cụ Ahrefs. Do vậy, bạn chặn Ahrefs thu thập dữ liệu trên Website của bạn thông qua File Robots.txt
File file robots.txt dùng để làm gì?
Một số người làm SEO sử dụng file robots.txt với mục đích chính là ngăn chặn Googlebot vào thu thập dữ liệu trên Website của họ trong khi Website đang xây dựng. Nhưng bạn có biết file robots.txt có rất nhiều công dụng khác không? Tất cả các công dụng của file robots.txt:
- Chặn Google thu thập dữ liệu trong khi Website đang được xây dựng: trong khi website của bạn đang được xây dựng, sẽ có rất nhiều lỗi và có những phần chưa hoàn chỉnh. Và bạn không muốn Google thu thập dữ liệu, vì nếu như vậy Google sẽ đánh giá Website của bạn là website kém chất lượng, như vậy sẽ ảnh hưởng rất lớn tới quá trình SEO sau này!
- Ngăn chặn các công cụ SEO thu thập dữ liệu để cho đối thủ phân tích website của mình: Ví dụ như công cụ Ahrefs, công cụ Semrush,…sẽ vào website của bạn và thu thập dữ liệu như số bài viết trên website, nội dung nào đang TOP Google, từ khóa nào đang TOP…Và sau đó, các đối thủ của bạn có thể dễ dàng phân tích Website của bạn.
- Không cho các công cụ vào thu thập các trang bí mật, các trang nội bộ: ví dụ bạn không muốn cho các công cụ thu thập URL của trang quản trị admin, như vậy sẽ lộ URL trang quản trị và có thể bị hacker tấn công website
- Không cho Googlebot thu thập các trang không cần thiết: ví dụ các trang không cần thiết như các file Javascript, các file CSS, các file Ajax,…Vì các file đó có ít giá trị, nên bạn sẽ chặn Google index.
- Cho các trình thu thập dữ liệu biết vị trí Sitemaps trên Website của bạn: Sitemaps là một tấm bản đồ giúp cho Google có thể tìm thấy các URL trên Website của bạn và index chúng nhanh chóng.
- Ngăn chặn quá nhiều bot vào thu thập cùng lúc dẫn đến Website bị chậm: bạn dùng lệnh Crawl-delay để cài đặt thời gian mà các con bot của trình thu thập dữ liệu cần đợi để thu thập trang tiếp theo trên Website của bạn. Ví dụ bạn yêu cầu con bot cần đợi 5 giây giữa mỗi trang mà chúng thu thập thông tin thì bạn sẽ dùng Crawl-delay: 5 trong file robots.txt
Xem file robots.txt trên Website của bạn như thế nào?
Nếu bạn không biết file robots.xtx trên Website của mình đã tạo chưa thì bạn có thể vào theo url domain/robots.txt. Ví dụ Website của EZ Marketing sẽ là: ezmarketing.vn/robots.txt
Cấu trúc của file robots.txt
Cấu trúc của một file robots.txt có 4 thành phần chính đó là User-agent, Disallow, Allow, Sitemap. Để giải thích chi tiết hơn các mục trong file robots.txt thì mình sẽ lấy file robots.txt của EZ Marketing là ezmarketing.vn/robots.txt:
User-agent: *
Disallow: /wp-admin/
Disallow: /product-category/
Disallow: /product-tag/
Disallow: /product/
Disallow: /faq-items/
Allow: /tin-tuc/
Sitemap: https://ezmarketing.vn/sitemap_index.xml
Giải thích chi tiết:
- User-agent: Lệnh này chỉ định trình thu thập dữ liệu của công cụ tìm kiếm nào đó phải tuân theo quy tắc trong nhóm này. Đây là dòng đầu tiên của mọi nhóm quy tắc. Dấu hoa thị (*) đại diện cho mọi trình thu thập dữ liệu, ngoại trừ các trình thu thập dữ liệu AdsBot (bạn phải nêu rõ tên cho loại trình thu thập dữ liệu này). Ngoài dấu hoa thị (*) bạn có thể sử dụng: User-agent: Googlebot(yêu cầu Googlebot phải tuân theo quy tắc trong nhóm này). Hoặc User-agent: Bingbot(yêu cầu Bingbot phải tuân theo quy tắc trong nhóm này).
- Disallow: không cho phép trình thu thập dữ liệu của công cụ tìm kiếm nào đó không được thu thập dữ liệu trong các danh mục này. Ví dụ: Disallow: /product-category/: tức là trình thu dữ liệu không được thu thập các URL có phần đầu là ezmarketing.vn/product-category/… Nếu bạn không muốn cho Googlebot thu thập bất kỳ dữ liệu nào trên Website của bạn thì đơn giản, bạn chỉ cần thêm dòng Disallow: /
- Allow(chỉ áp dụng cho Googlebot): Ngược lại với Disallow, Lệnh Allow cho phép Googlebot có thể thu thập dữ liệu tại URL bắt đầu bằng danh mục đó. Ví dụ: Allow: /tin-tuc/: tức là bạn cho phép Googlebot có thể index mọi URL bắt đầu bằng ezmarketing.vn/tin-tuc/…Lệnh Allow này sẽ ghi đè lệnh Disallow: tức là nếu bạn dùng lệnh Disallow không cho phép trình thu thập dữ liệu của thư mục cha, thì bạn vẫn có thể cho phép trình thu thập thu thập dữ liệu của thư mục con nằm trong thư mục cha đó. Ví dụ bạn Disallow thư mục /tin-tuc/ nhưng trình thu thập dữ liệu vẫn có thể được phép thu thập dữ liệu của thư mục /tin-tuc/tin-tuc-seo/…nếu bạn sử dụng lệnh Allow.
- Sitemap: cho các trình thu thập dữ liệu biết vị trí Sitemaps trên Website của bạn
Nói chung, các phần giải thích của mình ở trên về cấu trúc file robots.txt đã khá chi tiết và đầy đủ. Nếu bạn muốn tìm hiểu sâu hơn về file robots.txt bạn có thể tham khảo chi tiết về robots.txt của Google tại https://developers.google.com/search/docs/advanced/robots/create-robots-txt?hl=vi
Cách tạo file Robots.txt như thế nào?
Có 2 cách tạo File Robots.txt:
Cách 1: Sử dụng Yoast SEO để tạo file Robots.txt
Lưu ý: Bạn phải sử dụng WordPress thì bạn mới có thể cài đặt plugin Yoast SEO.
Để tạo file Robots.txt, hãy làm theo các bước dưới đây:
Bước 1: Vào trang quản trị của WordPress => Sau đó Hover vào mục Yoast SEO => Chọn Tools: như hình dưới đây

Hover mục Yoast SEO => Chọn Tools
Bước 2: Sau khi click “Tools” => Bạn click tiếp “File editor” như hình dưới: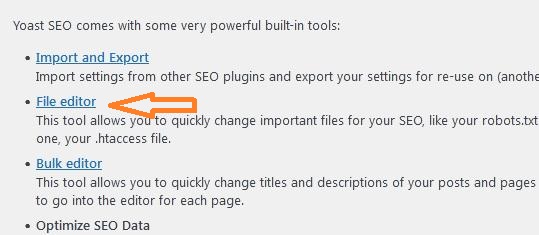
Bước 3: Sau khi click File editor bạn sẽ vào được file robots.txt. Tại đây bạn có thể chỉnh sửa thoải mái file này: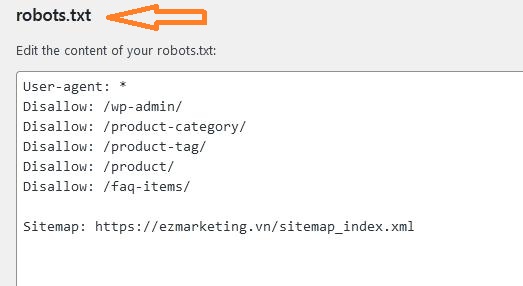
Cách 2: Tự tạo 1 File robots.txt ở dưới máy tính và upload lên thư mục gốc của Website
Bước 1: Tạo 1 file có tên robots.txt trên máy tính của bạn: Việc tạo 1 file trên máy tính không có gì khó khăn với bạn đúng không? Bạn chỉ cần tạo 1 file có tên là robots.txt trên máy tính của bạn. Sau đó, nội dung trong file đó thì bạn làm theo hướng dẫn trong phần “Cấu trúc của file Robots.txt“
Bước 2: Upload file robots.txt lên thư mục gốc của website: Nếu bạn không hiểu về hosting thì bạn có thể nhờ ai đang quản trị hosting chèn file robots.txt bạn vừa tạo lên thư mục gốc chứa website của bạn. Còn nếu bạn biết quản trị hosting thì bạn vào mục public_html trên hosting và tìm đến thư mục chứa website và upload file robots.txt vào thư mục chứa website của bạn là xong!
Dùng file Robots.txt để chặn các công cụ khác thu thập dữ liệu từ Website của bạn
Vì sao phải chặn các công cụ khác thu thập dữ liệu từ Website của bạn?
Mục đích của việc chặn các công cụ khác index Website của bạn là không để đối thủ của bạn phân tích Website của bạn đang có những backlink nào trỏ về, Website của bạn đang có những từ khóa nào đang lên TOP.
Ví dụ: chặn Ahrefs phân tích Website của bạn sẽ làm cho đối thủ không thể phân tích được backlink trỏ về Website của bạn, đối thủ cũng không biết bạn đang có những từ khóa nào đang TOP trên Google…từ đó Website của bạn sẽ là một bí ẩn trong mắt đối thủ!
Cách dùng File Robots.txt để chặn các công cụ khác thu thập dữ liệu
Bạn có thể chặn các công cụ khác thu thập dữ liệu trên Website của bạn. Bạn có thể chặn Google, Bing, Ahrefs,…và tất cả các công cụ khác. Nếu bạn muốn chặn tất cả các công cụ thu thập dữ liệu bạn chỉ cần thêm dòng User-agent: * là Ok!
- Nếu bạn muốn chặn Google Bot sử dụng dòng sau trong file robots.txt: User-agent: Googlebot
- Chặn Ads Bot thì thêm dòng: User-agent: AdsBot-Google
- Chặn Bing thì thêm dòng: User-agent: Bingbot
- Để chặn Ahrefs thu thập dữ liệu trên website của bạn thì thêm dòng: User-agent: AhrefsBot
- Để chặn Semrush thì thêm dòng: User-agent: SemrushBot
Làm sao để chặn Ahrefs và Semrush nhưng không chặn Google index Website của mình?
Nếu bạn muốn Google index Website của bạn nhưng không muốn các công cụ khác như Ahrefs và Semrush vào lấy dữ liệu website của bạn rồi cho đối thủ dễ dàng phân tích website của bạn. Trong file robots.txt bạn thêm đoạn sau(đoạn trên là chặn Semrush, đoạn dưới là chặn Ahrefs):
User-agent: SemrushBot
Disallow: /
User-agent: AhrefsBot
Disallow: /
6 câu hỏi thường gặp nhất về file robots.txt
Dưới đây là 6 câu hỏi thường gặp nhất mà các SEOer thường gặp khi tạo ra file robots.txt:
1. Website của tôi có bắt buộc phải có file robots.txt không?
Câu trả lời là: Không bắt buộc. Nếu bạn cần dùng file robots.txt với các mục đích ở trên thì mới cần tạo file này trên Website của bạn.
2. Tôi có thể đặt File robots.txt trong một thư mục con không?
Không. File robots.txt bắt buộc phải được đặt trong thư mục gốc của website của bạn, tức là trên hosting của bạn thì bạn phải đặt file robots.txt vào thư mục public_html/thu-muc-chua-website-cua-ban/robots.txt
3. Tôi muốn chặn người khác đọc file robots.txt có được không?
Không được bạn nhé. File robots.txt cho phép nhiều người dùng đọc được.
4. Tôi có phải đưa vào một lệnh Allow để cho phép trình thu thập dữ liệu không?
Bạn không cần cho lệnh Allow vào robots.txt. Vì tất cả các trình thu thập dữ liệu sẽ ngầm hiểu là đã được cho phép thu thập dữ liệu nếu không có lệnh Disallow.
5. Điều gì sẽ xảy ra nếu file robots.txt của tôi chứa lỗi?
Các trình thu thập dữ liệu vẫn sẽ thu thập dữ liệu nếu file robots.txt có lỗi nhỏ. Trường hợp tệ nhất là trình thu thập dữ liệu sẽ bỏ qua những lệnh không chính xác/lệnh bị lỗi.
6. Nếu tôi thay đổi các lệnh trong file robots.txt thì mất bao lâu để những thay đổi đó của tôi tác động đến kết quả tìm kiếm?
Đầu tiên, bạn cần xóa bộ nhớ đệm(cache) của tệp robots.txt và thông thường sau 1 ngày nó sẽ được cập nhật các công cụ tìm kiếm cập nhật lại.
Mong bài viết đã giúp bạn trả lời được những câu hỏi liên quan tới file Robots.txt. Nếu có bất kỳ thắc mắc nào về file robots.txt, hãy để lại dưới phần bình luận và chúng tôi sẽ sớm giải đáp thắc mắc của bạn!
Nếu bạn muốn Google index trở lại Website thì bạn có thể xem bài viết: Các cách để Google Index nhanh




Hãy để lại bình luận